First, a disclaimer: the title of this post is obviously exaggerated. Proof is an awfully big word to throw around, and although I employed pretty good experiment design practices and statistical checks, I can’t really prove that Reddit should do this or that. But I can show that what they are doing now is not working, at least when it comes to search.
So, I got an email the other day letting me know that my article, Tagging and Searching: Search Retrieval Effectiveness of Folkonsomies on the World Wide Web, is being published in the July 2008 issue of Information Processing and Management (here’s the official DOI link to the article). In the study I compared search performance between traditional search engines (like Google), subject directories (like Open Directory), and social bookmarking systems (like Reddit) and their folksonomies.
What’s a folksonomy? The word is a play on the term taxonomy – a taxonomy is a system of organizing and categorizing things, like the Dewey Decimal System. Taxonomies usually follow very strict rules and are controlled by experts. A folksonomy is a system of organization built by large numbers of regular users, who add things to the collection, evaluate them, and usually tag them with keywords.
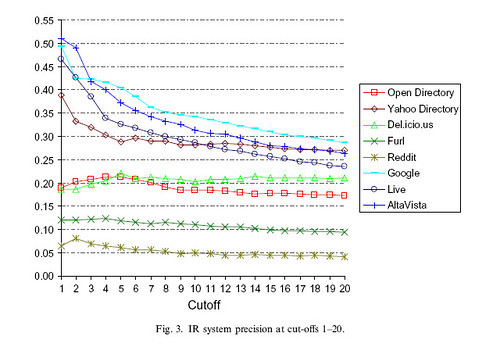
In my study, the social bookmarking systems with tagging systems did surprisingly well – Del.icio.us was more precise than Open Directory, and at a cut off of 20 results it’s precision was fairly close to that of the search engines.
Reddit, however, did not fare so well. It consistently had the lowest precision, meaning that searches returned very few relevant results. There could be many reasons for this, but the biggest difference between Reddit and the others is the lack of tags.
Now, it’s possible that the folks at Reddit have no interest in search, or information retrieval in general. I think Reddit is very effective at bringing out new and interesting links on a daily basis and encouraging commentary (just my opinion, no stats to back that up). But I think it’s a big missed opportunity not to add tagging and see where it leads.
(One last disclaimer: this post is my personal opinion as someone who enjoys using Reddit and does not reflect on my employer. This post refers to research done independently as a grad student.)