After my first expose to the Dialog structured search system I wanted to put down some thoughts about relational databases. There may very well be reasons why flat-file text databases are better for systems like Dialog or OhioLink, but I really don’t think they are the ones I’ve heard mentioned in class.
The first major point made in class was that in a flat file database like those in dialog the creators could do something like this for a record with multiple authors:
TI = Title of this article
AU = Smith, Bob B
AU = Jones, Joseph H
AU = Fakename, Robert P
etc…
Whereas in a relational database the table would have to have fields like this:
Table Article
——————
Title
Author1
Author2
Author3
etc…
Although I have seen databases designed exactly as described, that that design defeats the entire point of having a “relational” database–relationships. A better design would be to break Articles and Authors into two separate tables, since they are two separate entities, and because they have a many-to-many relationship (any number of authors can write any number of articles) a link table would be made as well:
Table Article
——————
Article_id
Article_title
Table Author
——————
Author_id
Author_name
Table Article_Author
——————
Article_author_id
Article_id
Author_id
This is a better approach than the flat file database as well, because it means an author only needs to be entered once, and that the author record only exists in one place. If a user is typing up hundreds of citations a day, it is likely they will misspell an author name once and a while–with the relational database, they would be picking from a dropdown or using some other method to select the author record that already exists. Also, it allows for changes to be made easily. Imagine if a prolific author has adopted a stage name and gained notoriety–now the author record can be changed only once and the changes will be reflect every time an article record–joined to the author table–is called up.
But what if some users will still search for the author’s old name? There are a number of approaches the database designer could take, for example creating a new Author_aliases table that links to the correct record in the Author table, etc. Also, the tables above are highly simplified. It is doubtful the author table would have a field for name–most likely it would have fields for first, middle, and last name and any other pertinent information as well. That, and proper construction of the interface, would eliminate such silliness as having to type Lastname, First in one place and Lastname First Initial in others.
There are a number of good tutorials on this subject online, for example:
http://www.phpbuilder.com/columns/barry20000731.php3?page=1
http://www.serverwatch.com/tutorials/article.php/1549781
http://builder.com.com/5100-6388-1050841.html
The second issue brought up in class was the need for unlimited field size. I have also seen relational databases where the designer only allowed 5 characters for a field that after a year really needed 10, but again this is poor design. Relational databases, at least for the last ten years or so, have been able to handle more or less unlimited field sizes. MySQL, which is available for free, is a good example. (http://www.mysql.com/documentation/mysql/bychapter/manual_Reference.html#Column_types) For numerical data, the bigint column type has a range of -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 or 0 to 18,446,744,073,709,551,615 unsigned, and the varchar type supports up to 255 characters. If you need more room than that, the longtext type supports up to 4,294,967,295 characters. War and Peace in ASCII from the Gutenberg project, is just over 3 million characters. How often do you need to store more than 1,000 copies of war and peace in one column of one record? Expensive commercial databases like Oracle no doubt have even more impressive figures.
There are reasons why most of the largest web sites with the most traffic and largest amount of information use relational database backends, and not CSV files or even XML for storage and retrieval. XML is great at moving, exchanging, and marking up information for display. But from what I’ve read most people seem to agree it’s not great for storage of anything of real size, or anything that needs to be accessed very often and very quickly.
The more I use Dialog the less impressed I am by it. It strikes me very much as a tool that was amazing in its day, but severely limited by available hardware. Now that hardware is ridiculously fast and cheap, its limitations are purely artificial and indistinguishable from clunky design. I know many people who swear by command-line interfaces, and I know there are studies showing CLI to be more “efficient” for the most expert of users, but there has to be a reason why 99% of the world uses Windows or MacOS (or Gnome or KDE even if they run Linux). If it takes a year for most users to reach expert status and reap the efficiency benefits, but users can master a 20 percent less efficient GUI in a week, which is better? And I say that from the point of view of someone who used DOS for years and is comfortable coding in notepad. And it’s not as if creating a GUI means you have to abandon the CLI completely–both can happily coexist.
There are some major structural problems. The fact that Author name entry isn’t standard across Dialog is nonsensical. I understand where some fields in chemistry databases will differ from fields in business databases, but nearly everything will have an author, and all that do should conform to a standard. The advantages of controlled vocabulary dwindle when nothing is well controlled. Descriptors differ from one database to another, may or may not be updated, etc. A well-designed relational database would help to eliminate these sorts of problems.
It would not be hard to make a system like Dialog with a relational database. Give a decent programmer or dba complete access to Dialog’s data and a year full-time, and I bet they could come up with something. The biggest problem would be trying to reconcile all the weirdness of the individual databases, like truncating hyphenated names and such. Designing the tables and fields in MySQL for ERIC and a couple others would be a fun little project that would take less than a week.
I wonder – has there been any effort to bring Dialog into the current decade, or even the 1990s? How many people still actually use it, with so many library and journal catalogs going online? I know Medline is available elsewhere. I asked a friend of mine majoring in LS at Pittsburgh and she said one professor showed it to them in one class, but no one ever actually used it. I understand the difference between being able to search fields vs the web, controlled vocab, etc., but surely there’s a less aggravating system out there that includes these features?
I mean, just the whole bluesheet thing… searching with the Find on this Page feature of your browser? You should never rely on your visitors to have a specific browser feature, and search boxes aren’t too hard to do. The Dialog Database Catalog is a series of randomly chopped up PDFs? And none of this is integrated into any of their telnet-workalike interfaces?
 Earlier I wrote about using Photoshop to create a heat map and to use data maps when house hunting. I got a pretty good response to those tutorials but the process is a little too labor intensive for most. So when I moved to California, I decided to do something similar, using the Google Maps API, so that it would be easy for anyone to make their own heat map.So here it is: Localographer – build interactive heat maps for house and apartment hunting. You can see a screenshot below:
Earlier I wrote about using Photoshop to create a heat map and to use data maps when house hunting. I got a pretty good response to those tutorials but the process is a little too labor intensive for most. So when I moved to California, I decided to do something similar, using the Google Maps API, so that it would be easy for anyone to make their own heat map.So here it is: Localographer – build interactive heat maps for house and apartment hunting. You can see a screenshot below: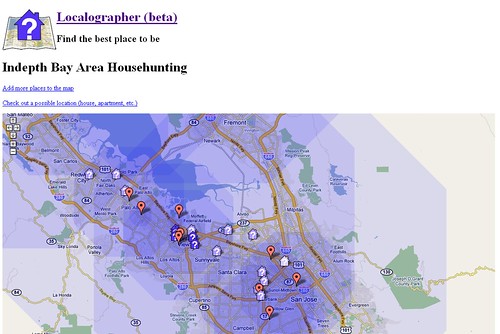 Localographer is a beta release right now, so watch out for bugs and random downtime. Also, I have to add a disclaimer: this is not an official Google project, this is something I did on my spare time. In fact, most of the work was done before I started working at Google in preparation for our move to California.The site takes you though a series of steps to build your map:
Localographer is a beta release right now, so watch out for bugs and random downtime. Also, I have to add a disclaimer: this is not an official Google project, this is something I did on my spare time. In fact, most of the work was done before I started working at Google in preparation for our move to California.The site takes you though a series of steps to build your map: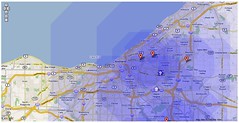
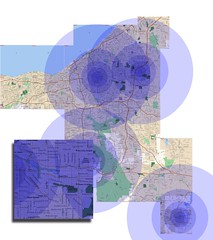 In case you’re interested, the site was developed in PHP with a MySQL database. The maps use the Google Maps API with some hand-written functions to correctly draw the hot spots.Please take a look and let me know what you think. Post and problems, bugs, or new feature ideas in the comments below. Later I’ll post a poll so you can vote on new features and other enhancements.
In case you’re interested, the site was developed in PHP with a MySQL database. The maps use the Google Maps API with some hand-written functions to correctly draw the hot spots.Please take a look and let me know what you think. Post and problems, bugs, or new feature ideas in the comments below. Later I’ll post a poll so you can vote on new features and other enhancements.